I. Les protéines sont l'expression primaire de l'information génétique
• A. La relation gène-protéine : une expérience historique
• B. La séquence des nucléotides du gène commande la séquences acides aminés de la protéine
• L'essentiel
II. La protéosynthèse s'opère en deux temps
A. L'ADN est d'abord transcrit en ARN dans le noyau
TP1. Le code génétique
B. L'ARNm est ensuite traduit en protéine dans le cytoplasme
• L'essentiel
III. Un même gène pour plusieurs protéines
• A. Une apparente contradiction
• B. Les eucaryotes possèdent des gènes morcelés
• C. L'épissage alternatif est source de diversité
• L'essentiel
BILAN
Ces souris sont fluorescentes lorsqu’elles sont exposées aux rayons ultraviolets. Elles sont devenues capables de produire une protéine, la GFP (green fluorescent protein), après avoir reçu un gène présent naturellement chez une méduse (Aequorea victoria).
Image : SVT 2e, Hatier 2010, p. 51
OBJECTIF
● L'information génétique est localisée dans le noyau des cellules et commande des caractères qui sont observables extérieurement.
● On recherche comment s'exprime l'information génétique.
 2
2 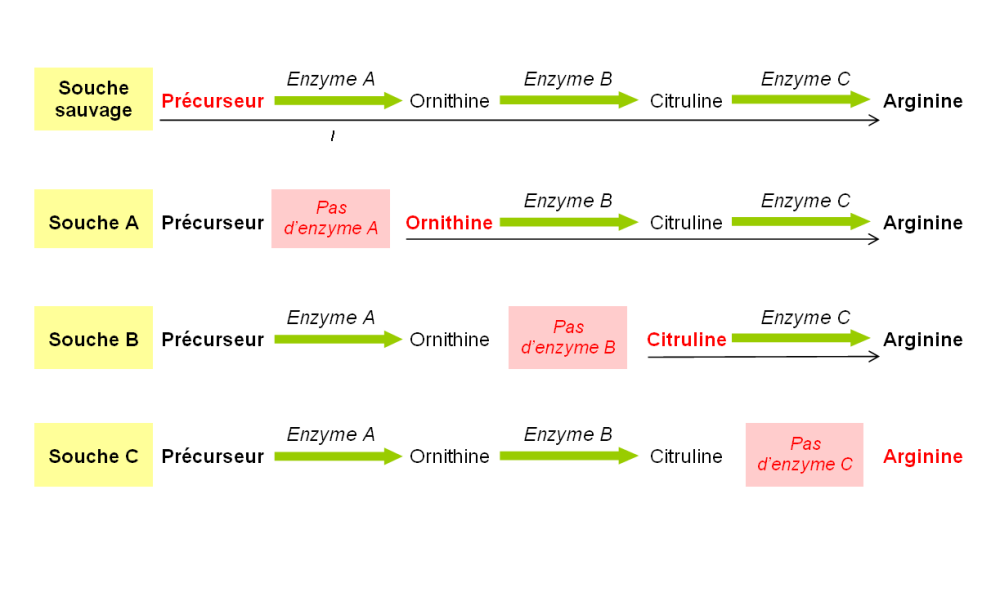
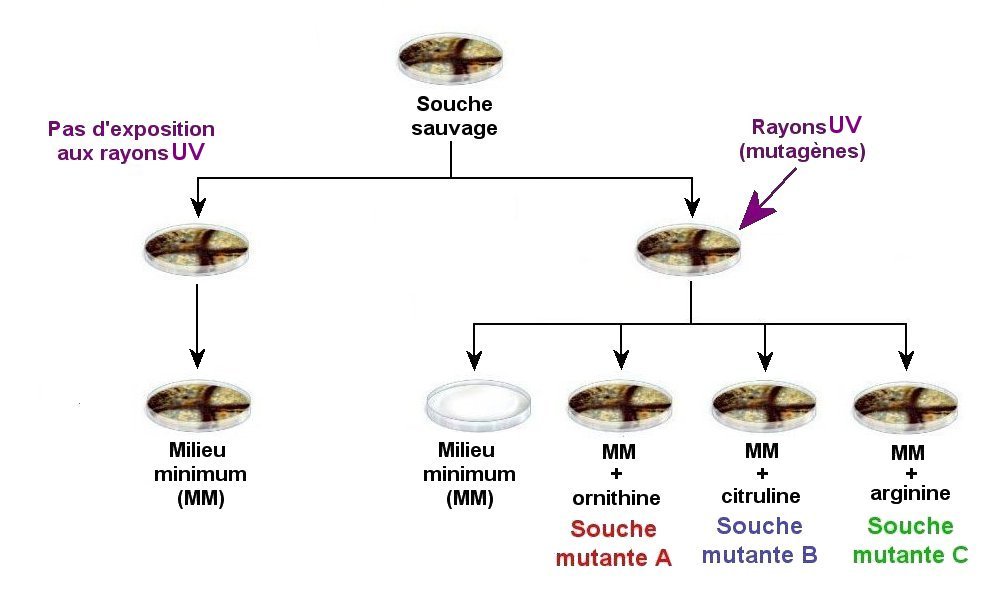
1 Expérience de Beadle et Tatum (1941) - 2 Interprétation de l'expérience de Beadle et Tatum
Après exposition aux UV du champignon Neurospora crassa (1), on obtient des souches mutantes (A, B, C), déficientes pour la synthèse de l’arginine (un acide aminé) et qui ne prolifèrent que si l'on ajoute au milieu le composé intermédiaire qu'elles ne savent plus fabriquer du fait d'une protéine enzymatique non fonctionnelle. Cette expérience a montré le lien direct gène-enzyme, qui a ensuite été élargi au lien gène-protéine (car les enzymes sont des protéines).
Un gène est une unité d'information, contenue dans l'ADN et qui permet la synthèse d'une protéine par une cellule. Les autres molécules du vivant (lipides et glucides) ne sont pas l'expression directe de l'information génétique, même si leur métabolisme est commandé par celle-ci.
Source : www.lps.ens.fr

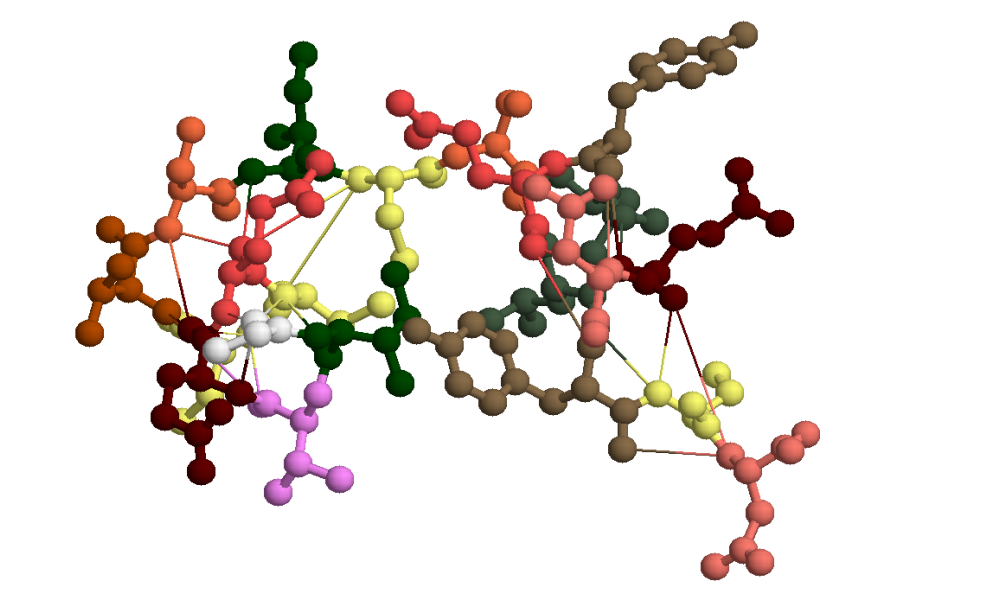
L’hémoglobine est une protéine qui assure le transport du dioxygène dans les hématies (globules rouges). Elle est formée de quatre sous unités identiques deux à deux, les globines. Chez l’homme adulte, il s’agit de deux chaînes alpha (en vert et bleu sur l'image) et deux chaînes bêta (l'une en jaune et l'autre colorée par acides aminés sur l'image). Chaque chaîne est formée d'une séquence d'acides aminés reliés entre eux par des liaisons fortes (c'est un polymère). Par repliements successifs elle acquiert une structure tridimensionnelle déterminée, ou conformation, grâce à des liaisons faibles, établies entre divers acides aminés éloignés sur la molécule (que ce soit sur la même chaîne ou sur des chaînes différentes). La fonction d'une protéine est liée à sa conformation.
Traitement obtenu avec le logiciel Rastop
l'insuline est une hormone qui intervient dans la régulation du taux de glucose dans le sang. C'est une molécule protéique formée de deux chaînes (A et B). Sur cette représentation de la chaîne A on distingue les liaisons fortes (bâtonnets épais), qui relient les acides aminés adjacents entre eux, et les liaisons faibles (bâtonnets fins), qui relient des acides aminés non adjacents et qui assurent la conformation de la molécule.
Traitement obtenu avec le logiciel RasTop
 2
2 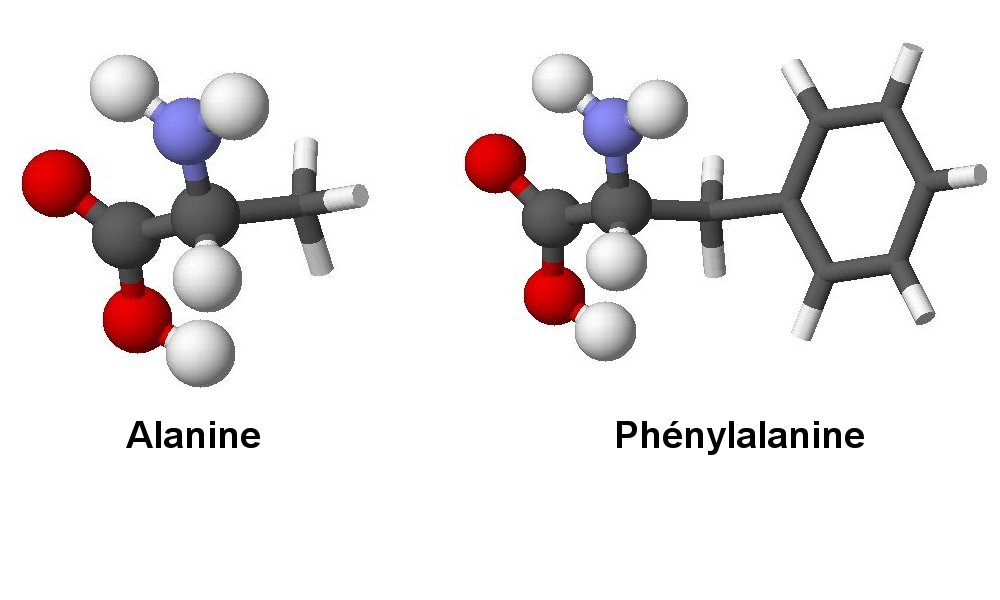 3
3  4
4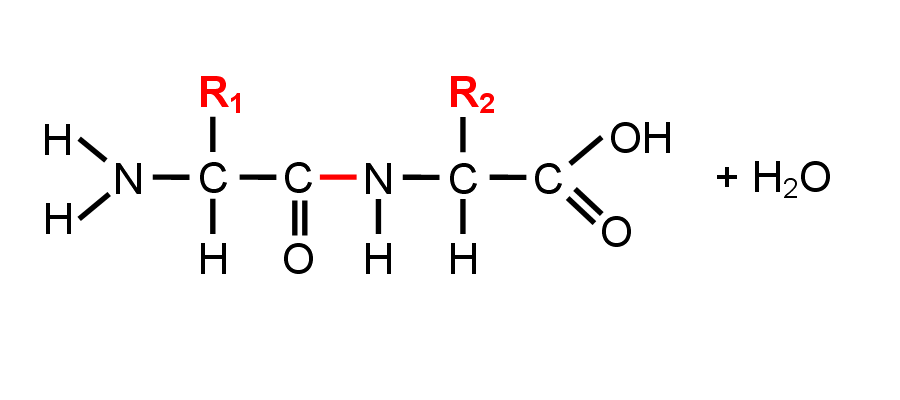
1 Les 20 acides aminés - 2 Représentation moléculaire de deux acides aminés - 3 Organisation d'un acide aminé - 4 La liaison peptidique
Il existe 20 acides aminés naturels différents (1). Par commodité on les désigne par une abréviation de trois lettres ou par un symbole constitué d'une lettre majuscule. Ils possèdent tous un motif commun : CH + groupe carboxyle COOH + groupe amine NH2 (3 et en boules sur 2) et diffèrent par un radical R (en bâtonnets sur 2). Deux acides aminés successifs sont reliés par une liaison forte : la liaison peptidique (3).
Image 2 : traitement obtenu avec le logiciel Rastop.
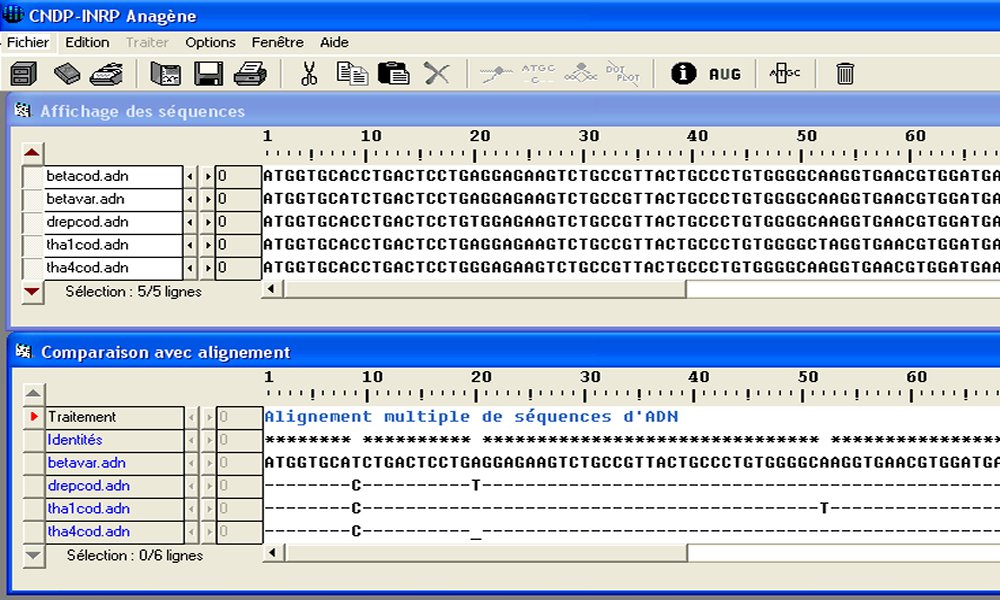
* indique une identité pour toutes les chaînes étudiées, – signifie une identité avec la chaîne de référence (betacod) et – – indique qu’un nucléotide (celui du milieu) est manquant.
Il existe divers allèles de la bêtaglobine humaine dont betacod, betavar, drepcod, tha1cod et tha4cod. Les individus porteurs d’un ou deux exemplaires des allèles betacod ou betavar ne sont pas malades. Ceux qui portent l’un des autres allèles en double exemplaire possèdent des bêtaglobines défaillantes et souffrent de drépanocytose pour drepcod ou de thalassémies pour tha1cod et tha4cod. Ce sont de graves anémies qui affectent fortement la vie de l'individu.

Les bêtaglobines codées par betacod et betavar ont des séquences d'acides aminés identiques (146 acides aminés). Par contre les bêtaglobines codées par drepcod (146 acides aminés dont une substitution), tha1cod (17 acides aminés) et tha4cod (18 acides aminés) ont des séquences d'acides aminés différentes.
Une modification de la séquence des nucléotides du gène de la bêtaglobine (ou mutation), peut entraîner une modification de la séquence des acides aminés de la protéine qui, à son tour, pourra entraîner une modification de sa conformation et, généralement, une modification de sa fonction. C'est ce qui explique les anémies observées dans le cas des bêtaglobines.
Traitements obtenus avec le logiciel Anagène
● Un gène est une unité d'information, contenue dans l'ADN et qui gouverne la synthèse d'une protéine par une cellule. Une protéine est formée d’une ou plusieurs chaînes polypeptidiques qui sont des polymères linéaires d’acides aminés liés par liaison forte. En outre, des liaisons faibles peuvent s’établir entre des acides aminés distants sur une même chaîne, ce qui entraîne des repliements, ou appartenant à des chaînes différentes, ce qui lie les chaînes entre elles. La protéine fonctionnelle a donc une structure tridimensionnelle, ou conformation spécifique. Il existe vingt acides aminés naturels qui ne diffèrent que par la nature de leur radical R.
 Acide aminé
Acide aminé ● L'ordre et la nature des acides aminés (ou séquence) d’un polypeptide dépend de la séquence des nucléotides de l’ADN du gène qui le code. Une mutation, peut entraîner une modification de la séquence des acides aminés qui, à son tour, pourra entraîner une modification de la conformation de la protéine et, généralement, une modification de sa fonction. La séquence des nucléotides de la molécule d'ADN représente donc une information génétique qui dicte la séquence des acides aminés des protéines. Seules les protéines sont l’expression directe de l’information génétique. Ce n’est pas le cas des autres molécules du vivant (lipides et glucides) même si leur métabolisme est commandé par l’information génétique.

Des cellules animales sont cultivées sur un milieu contenant un acide aminé marqué. Le noyau (N) de certaines cellules a été enlevé (E) quelques minutes avant la mise en culture. On réalise ensuite une autoradiographie.
Alors que l'information génétique se trouve dans le noyau, on constate que le noyau n'est pas indispensable à la synthèse protéique (= protéosynthèse) qui a lieu dans le cytoplasme.
Image : SVT 1eS, Hatier 2001 p. 50
Quand la culture s’est développée les cellules sont lavées de manière à éliminer toute trace de substrat radioactif non incorporé à une molécule. Par exemple toute trace d’acide aminé radioactif non incorporé à une protéine.
On réalise enfin une préparation microscopique que l’on dispose sur un film photographique argentique. Celui-ci est impressionné par le rayonnement radioactif. Après développement du film on observe des points noirs sur les clichés aux endroits où se trouvent les molécules marquées.

Le vert de méthyle colore l'ADN en vert et la pyronine colore l'acide ribonucléique, ou ARN, en rouge.
Contrôle.
- Si on traite une coupe par la ribonucléase, qui détruit (dépolymérise) l'acide ribonucléique, la coloration vert de méthyle-pyronine colore simplement l'ADN restant dans le noyau en vert.
- Si on traite une coupe par la désoxyribonucléase, qui détruit (dépolymérise) l'acide désoxyribonucléique, la coloration vert de méthyle-pyronine colore simplement l'ARN restant dans le noyau en rouge.
Image : jean-jacques.auclair.pagesperso-orange.fr
 2
2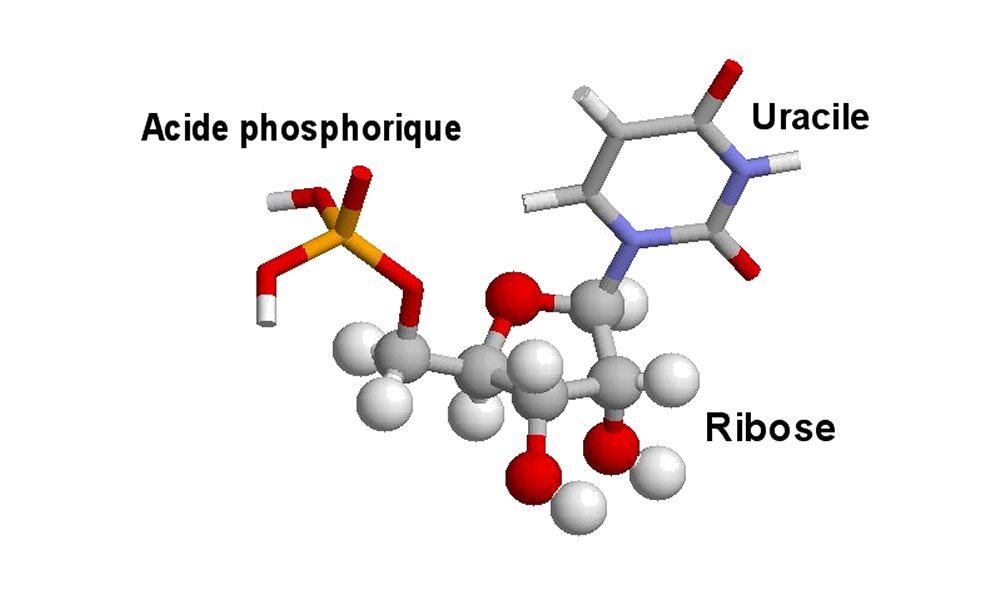
1 Segment représentatif de molécule d’acide ribonucléique (ARN) - 2 Nucléotide à uracile
L’ARN (1) est une molécule constituée d’une séquence n'excédant pas quelques milliers de ribonucléotides, ne comportant qu'un seul brin et de courte durée de « vie ». Chaque ribonucléotide (2) est formé par l'association d'un acide phosphorique (représenté en bâtonnets) qui relie les nucléotides entre eux, d'un ribose (glucide, représenté en boules et bâtonnets) et d'une base azotée (représentée en bâtonnets) : guanine (G), cytosine (C), adénine (A) ou uracile (U).
Traitement obtenu avec le logiciel Rastop
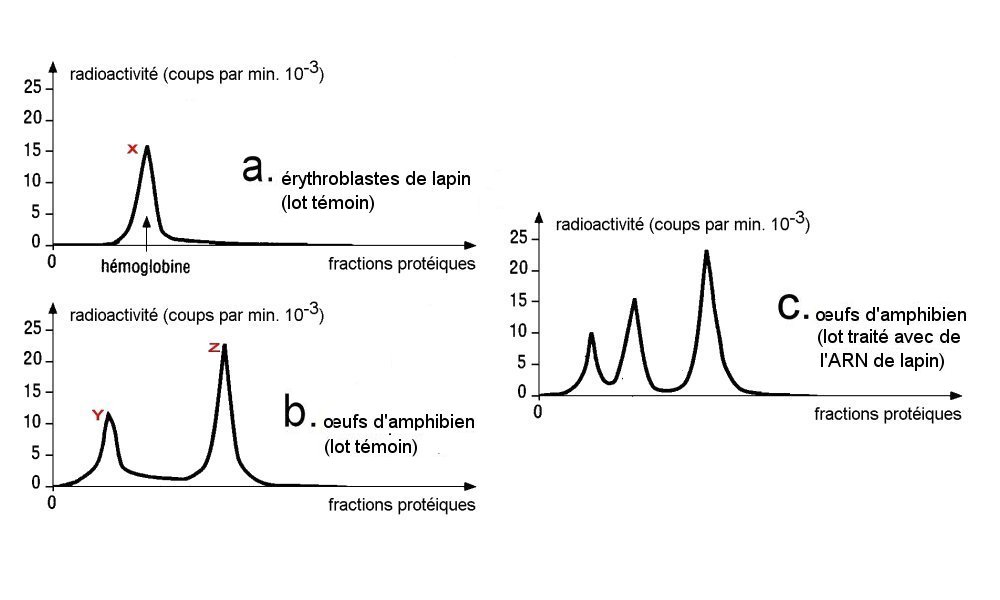
a. Des érythroblastes de lapin sont cultivés dans un milieu contenant un acide aminé radioactif, l’histidine. Les protéines fabriquées par les érythroblastes sont ensuite extraites et soumises à une électrophorèse qui montre un pic radioactif (X) spécifique de l’hémoglobine de lapin.
b. On fait incuber des œufs d’amphibien (le xénope) dans un milieu contenant de l’histidine radioactive. L’électrophorèse montre alors deux pics protéiques (Y et Z) spécifiques des protéines produites par les œufs de xénope.
c. On prélève de l’ARN dans le cytoplasme des érythroblastes de lapin, et on l’injecte dans des œufs de xénope que l’on fait ensuite incuber dans un milieu contenant de l’histidine radioactive. On réalise ensuite une électrophorèse.
On observe que les œufs d'amphibien expriment sous forme de protéine l'information apportée par l'ARN des érythroblastes de lapin.
Image : www.lfmadrid.net
L’électrophorèse est une technique de laboratoire qui permet de séparer les protéines d’un mélange en diverses fractions.
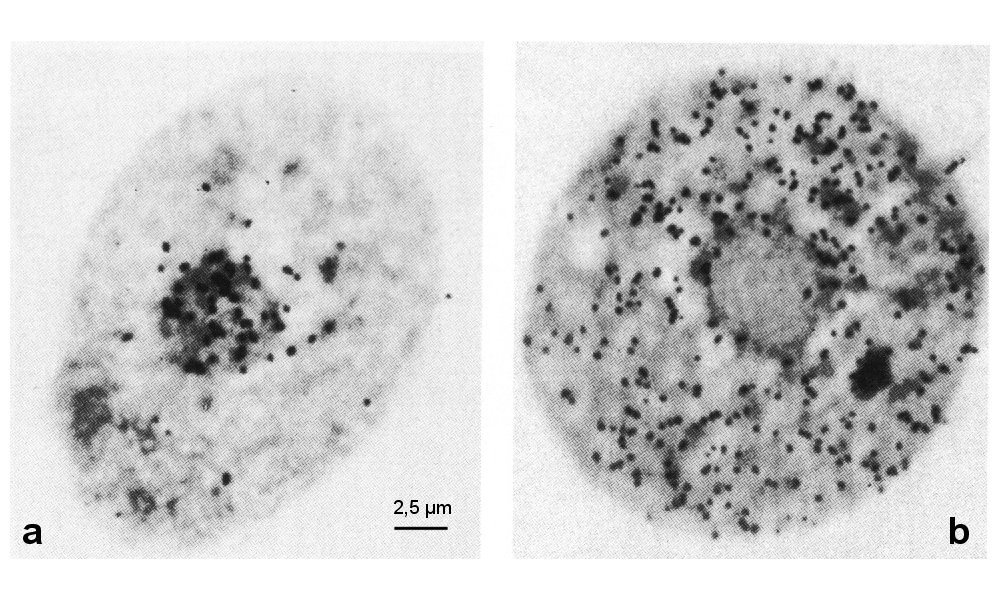
Des cellules animales sont cultivées sur un milieu contenant de l’uracile radioactif.
a. Autoradiographie après culture sur milieu radioactif pendant 15 minutes.
b. Autoradiographie après culture sur milieu radioactif pendant 15 minutes puis transfert sur un milieu de culture non radioactif pendant une heure et demie.
L'ARN est formé dans le noyau (a) mais, contrairement à l'ADN, on le retrouve peu après dans le cytoplasme (b).
Image : www.lfmadrid.net
 2
2 
1. Noyau (MEB après cryodécapage) - 2 Enveloppe nucléaire observée en coupe (MET)
N : noyau ; En : enveloppe nucléaire ; Pn : pores nucléaires.
L'enveloppe nucléaire est percée de nombreux pores (1) dont le diamètre est suffisant pour permettre le passage de l'ARN (2).
Images (modifiées) : SVT 1 e S Hatier 2001 p. 53 fig. 11 et 12
• Microscope électronique à transmission (MET). Un faisceau d’électrons traverse la préparation microscopique. Celle-ci est une coupe ultrafine traitée avec des métaux lourds qui se fixent sur les structures cellulaires et qui arrêtent alors les électrons (zones foncées sur les images). Le flux d’électrons qui traverse la préparation est élargi par des lentilles électromagnétiques (zones claires sur les images).
• Microscope électronique à balayage (MEB). Un faisceau d’électrons balaie la surface de l’échantillon préalablement recouverte de métaux lourds. En réponse, l’échantillon réémet des particules qui, analysées par différents détecteurs, permettent d’obtenir une image de la surface de la préparation.
Par analogie avec les appareils optiques le MET s’apparente au microscope photonique (MP) alors que le MEB s’apparente à la loupe.

L'ARN a une séquence de nucléotides identique à celle de l'ADN (brin non transcrit, voir ci-après). Seul l'uracile (U) remplace la thymine (T). Il supporte donc la même information.
Traitement obtenu avec le logiciel Anagène
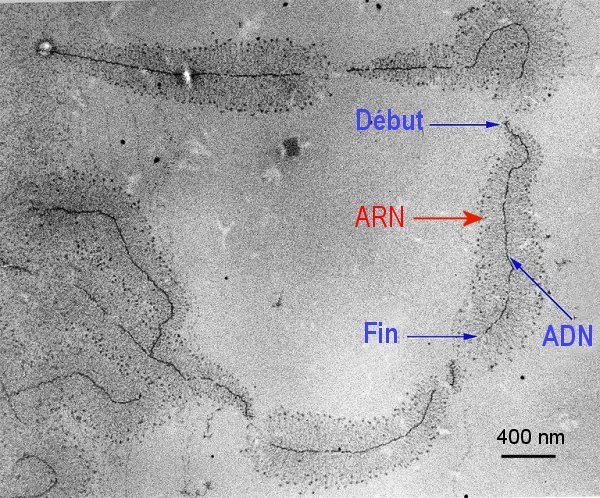
Ce type de structure est dit en « arbre de Noël ». Le « tronc » de l'arbre est constitué de l'ADN et les « branches » sont autant de molécules d'ARN en cours de synthèse. Celles-ci sont plus courtes vers le début de la région transcrite et plus longues vers la fin. Le cliché montre plusieurs « arbres de Noël », c'est à dire plusieurs séquences d'ADN en cours de transcription.
Image : fr.wikipedia.org
L'ARN polymérase (ARNpol) est une molécule enzymatique (ce n'est pas un organite visible au microscope) qui provoque localement l'ouverture de la double hélice d'ADN. C'est à son niveau que s'opère la synthèse de l'ARN car elle associe à chaque désoxyribonucléotide de la chaîne transcrite le ribonucléotide complémentaire (A à T, C à G, G à C et U à A). L’ARN obtenu est donc complémentaire du brin transcrit et identique, aux uraciles et riboses près, au brin non transcrit.
En France, selon les auteurs, l'expression brin codant désigne parfois le brin transcrit et parfois le brin non transcrit. Elle est donc à éviter.
Image : fr.wikipedia.org
Chaque gène est précédé d’une séquence promoteur, qui permet la fixation de l’ARNpol et indique le brin à transcrire ainsi que le début de la zone à transcrire. L'ARNpol progresse ensuite le long de l'ADN jusqu'à ce qu'elle rencontre un site de terminaison. Elle se détache alors de l'ADN et libère l'ARN formé.
Image : d'après www.chem.uwec.edu

- Si un nucléotide désigne un acide aminé on a alors 41 = 4 acides aminés possibles.
- Si deux nucléotides désignent un acide aminé on a alors 42 = 16 acides aminés possibles.
- Si trois nucléotides désignent un acide aminé on a alors 43= 64 acides aminés possibles.
Puisqu’il y a 64 combinaisons de trois nucléotides parmi quatre pour seulement 20 acides aminés, plusieurs combinaisons correspondent au même acide aminé.

En 1961, Crick et Brenner utilisent des bactéries qu'ils infectent avec un virus ayant été soumis à un agent mutagène qui provoque l'addition ou la délétion de nucléotides de l'ADN viral.
Si une mutation ne modifie qu'un ou deux acides aminés de la protéine virale impliquée dans l'infection, celle-ci reste fonctionnelle. Il faut trois ribonucléotides pour désigner un acide aminé. L'ajout ou la perte d'un ou deux nucléotides entraîne un décalage dans la lecture de l'information génétique.
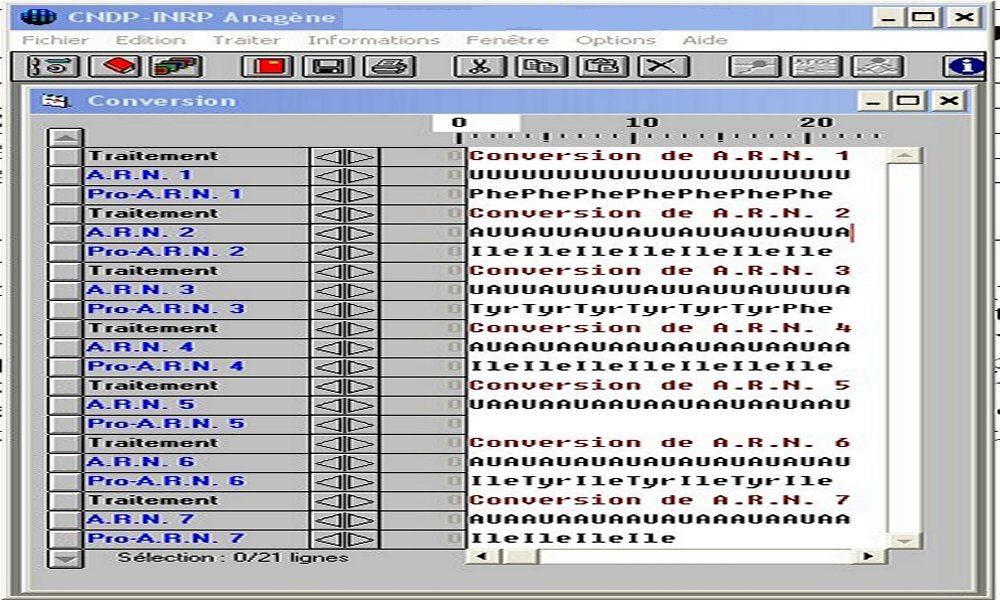
En 1961, dans un milieu contenant les 20 acides aminés ainsi que divers constituants cytoplasmiques, Nirenberg et Matthaei ajoutent un ARN de synthèse constitué, par exemple, d'une succession de nucléotides à uracile (poly U). Ils recueillent alors dans le milieu un polypeptide uniquement constitué de phénylalanine. Avec un ARN poly A ou poly C, ils obtiennent respectivement un polypeptide uniquement constitué de lysine, ou de proline. Ces expériences peuvent être modélisées grâce à un logiciel de traitement de données moléculaires. Les séquences d’ARN testées sont notées A.R.N. 1 à 7, les peptides correspondants sont notés Pro-A.R.N. 1 à 7. On appelle codon une séquence de 3 ribonucléotides ayant une signification dans le code génétique. Celui-ci est non chevauchant car un nucléotide n’appartient qu’à un seul codon.
Traitement obtenu avec le logiciel Anagène
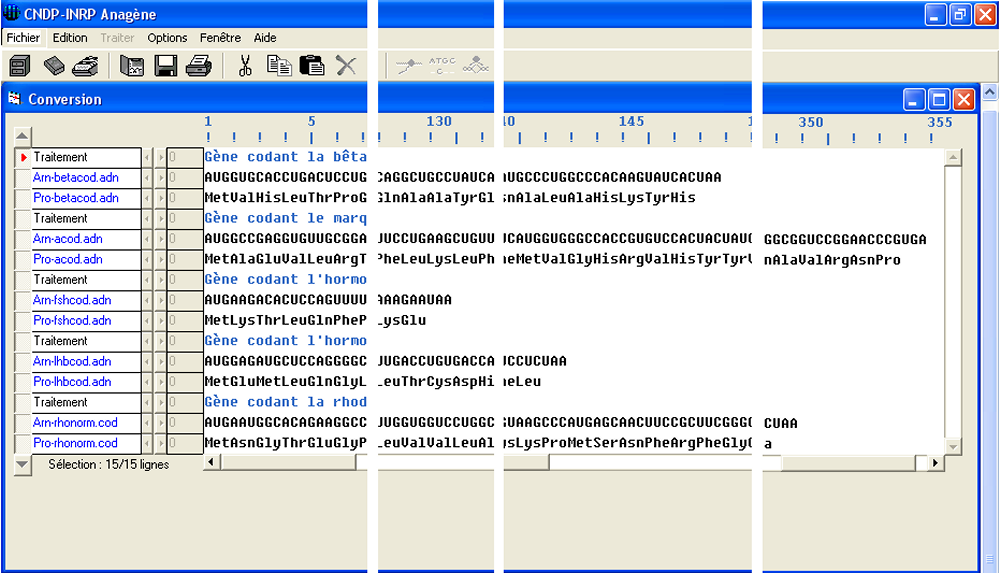
Toutes les séquences codantes d'ARNm commencent par le même codon AUG, qui code la méthionine (Met). C'est le codon d'initiation.
Toutes les séquences codantes d'ARNm finissent par un codon stop (UAA, UAG ou UGA) qui ne code aucun acide aminé.
Traitement obtenu avec le logiciel Anagène

En 1966, en testant les 64 combinaisons de trois ribonunucléotides ou codons, Khorana et son équipe, ont obtenu le décryptage complet du code génétique. La code génétique est non ambigu car soixante et un codons désignent chacun un seul acide aminé alors qu'il n'y en a que 20. Quatre codons ont un rôle particulier, de ponctuation. Le codon AUG code l’acide aminé méthionine mais indique aussi le début d’une traduction (codon d’initiation). Les codons UAA, UAG et UGA sont des codons stop qui indiquent la fin de la traduction. Le code génétique est redondant (= dégénéré) car plusieurs codons désignent le même acide aminé.

La protéine cdc2 est une molécule indispensable au bon déroulement du cycle cellulaire chez les eucaryotes. Non seulement on constate que la séquence de son ARNm est très voisine chez des espèces très différentes mais que les mêmes codons codent toujours les mêmes acide des aminés.
Source : www.inrp.fr et traitement obtenu avec le logiciel Anagène
Message : ensemble d’informations, organisées selon un code, qui circule d’un émetteur à un récepteur.
Messager : support d’un message.
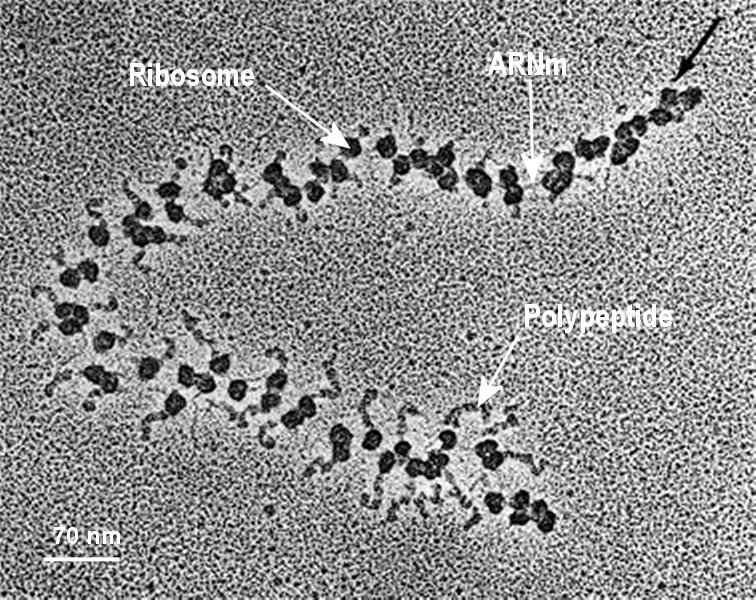
Les ribosomes sont des organites cytoplasmiques globuleux et de petite taille (20 à 30 nm de diamètre) mais visibles au ME. Ils permettent la synthèse d'un polypeptide à partir de l'information génétique portée par l'ARNm. La longueur du polypeptide est plus courte au début de la région traduite et plus longue vers la fin.
Image : tutoratp1.free.fr

Les ribosomes se fixent sur l'ARNm au niveau du codon d'initiation (AUG), puis progressent le long de la molécule. Pour chaque codon rencontré, chaque ribosome associe l’acide aminé correspondant dans le code génétique et catalyse la liaison chimique avec l'acide aminé précédent. Parvenus à un codon stop, le ribosome se sépare de l'ARNm et libère le polypeptide obtenu. La séquence de ce dernier est le reflet de la succession de codons de l'ARN, lui-même image de la séquence d'ADN qui a servi de matrice à sa synthèse.
Animation traduction (lien externe)
● Alors que l'information génétique se trouve dans le noyau, la synthèse protéique, ou protéosynthèse, a lieu dans le cytoplasme.
A. L'ADN est d'abord transcrit en ARN messager (ARNm) dans le noyau
● Comme l’ADN, l'acide ribonucléique messager, ou ARNm, est un support d’information produit dans le noyau mais il peut migrer dans le cytoplasme en passant par les pores de l’enveloppe nucléaire. Il présente en outre cinq particularités :
- il est formé d’un brin unique de nucléotides ;
- il ne dépasse pas quelques milliers de nucléotides car il ne correspond qu’à un seul gène ;
- le glucide des nucléotides est du ribose (ribonucléotides) ;
- l’uracile (U) remplace la thymine (T) ;
- sa durée de « vie » est courte (quelques heures en général).
● La transcription s'opère en trois étapes.
1. L’initiation. Sur l'ADN, chaque gène est précédé d’une séquence, ou promoteur, qui indique à la fois le brin à transcrire et le début de la zone à transcrire. Celui-ci permet également la fixation d’une enzyme : l’ARN polymérase (ARNpol).
2. L’élongation. L’ARNpol progresse le long de l’ADN et, en respectant la complémentarité des bases, associe un ribonucléotide à chaque désoxyribonucléotide rencontré. L’ARN obtenu est donc complémentaire du brin transcrit et identique, aux uraciles et riboses près, au brin non transcrit.
3. La terminaison. Quand l’ARNpol rencontre sur l’ADN un site de terminaison il y la libération de l’ARN qui pourra quitter le noyau en empruntant les pores nucléaires.
B. L'ARN messager est ensuite traduit en polypeptide dans le cytoplasme
● Le code génétique fait correspondre un acide aminé à trois bases successives de l’ARNm qui forment un codon. Il a quatre particularités :
- il est non ambigu, à un codon correspond un seul acide aminé ;
- il est dégénéré (ou redondant), plusieurs codons correspondent au même acide aminé ;
- il est non chevauchant, un nucléotide n’appartient qu’à un seul codon ;
- il est universel, c’est le même pour tous les êtres vivants (les exceptions sont très rares).
● La traduction s'opère en trois étapes.
1. L’initiation. Un ribosome se fixe au niveau du codon initiateur (AUG) de l’ARNm.
2. L’élongation. Le ribosome progresse le long de l’ARNm. À chaque codon rencontré il recrute un nouvel acide aminé selon le code génétique et l’associe par liaison forte à l’acide aminé précédemment recruté. Plusieurs ribosomes peuvent se succéder en même temps sur même molécule d'ARNm, l’ensemble forme alors un polysome.
3. La terminaison. Parvenu à un codon stop le ribosome se dissocie de l’ARNm et libère le polypeptide.
● Le polypeptide acquiert enfin sa conformation et s’associe éventuellement à d’autres polypeptides. Il forme alors une protéine fonctionnelle. Plusieurs gènes peuvent donc être nécessaires pour coder une protéine (cas de l'hémoglobine).

Le génome est l'ensemble du matériel génétique d'un organisme. De 1990 à 2003, le projet Génome humain a établi la séquence complète des 3,2 milliards de paires de bases (= paires de nucléotides) de l'ADN qui constituent le génome humain. Il a été mené à bien grâce à l'utilisation d'un grand nombre des séquenceurs qui décryptent automatiquement l'ADN. On a ainsi pu établir que le génome humain compte environ 25 000 gènes (20 à 30 000 selon les auteurs) alors que l’on pensait jusqu’alors qu’il y avait au moins 100 000.
Image : www.dfo-mpo.gc.ca
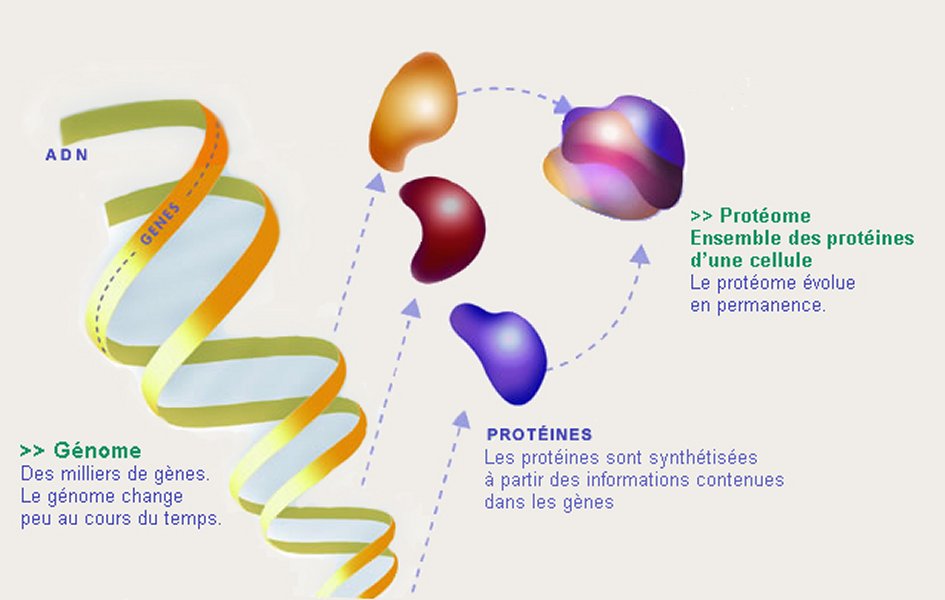
Le protéome est l’ensemble des protéines codées par un génome. Après le séquençage du génome humain, la communauté scientifique internationale est maintenant engagée dans l'inventaire du protéome humain (Human Proteome Project) qui est actuellement estimé à 100 000 protéines (1 000 000 pour certains auteurs). Dans ce cadre, la France est chargée de déterminer les protéines codées par le chromosome 14 (comme ce fut le cas pour le génome).
Image : image ORNL - U.S. Department of Energy Genomics : GTL Program sur interstices.info
 2
2 
1. Hybridation ADN-ARN (MET) - 2 Interprétation (A, B, C, D, E, F, G : boucles d'ADN non hybridé - 1, 2, 3, 4, 5, 6, 7 : brins hybrides ADN-ARN)
La molécule d'ADN du gène de l'ovalbumine de poule est chauffée ce qui casse les liaisons faibles et sépare les deux brins d'ADN. On ajoute alors l'ARNm correspondant à ce gène qui s'associe au brin d'ADN portant la séquence complémentaire et on obtient une hybridation ADN-ARN.
On observe qu'environ 75% du gène ne se retrouve pas sur l'ARNm.
Image 1 P. Chambon, Scientific American - mai 1981
 2
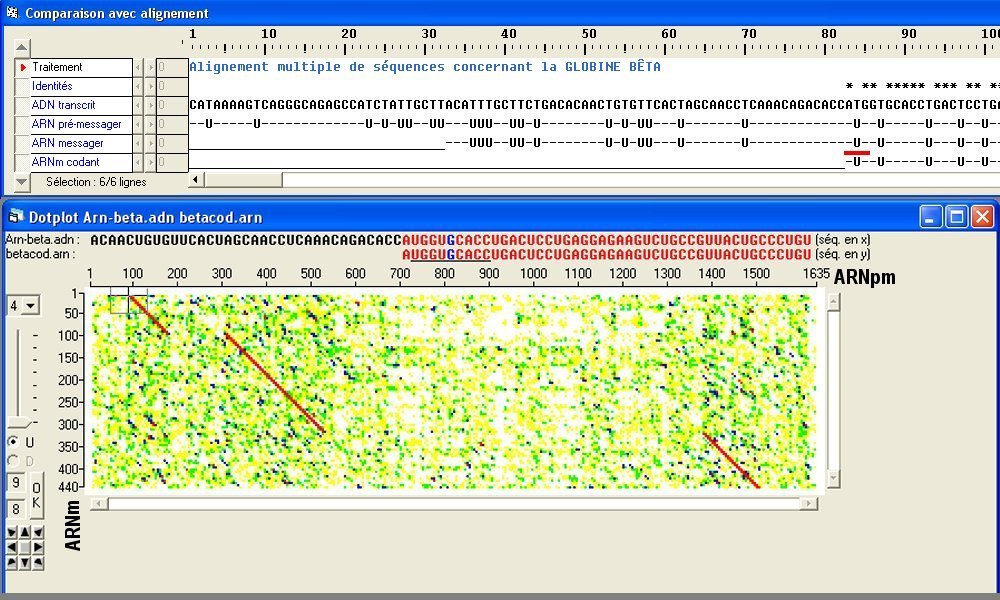
2 
1 Début de séquence et graphique de ressemblance du gène de la bêtaglobine et de son ARNm - 2 Comparaison des séquences du gène de la bêtaglobine et de son ARNm beta.adn : gène complet - Arn-beta.adn : ARN pré-messager - betarnm.arn : ARNm complet - betacod.arn : partie codante de l'ARNm.
Dans le noyau, l'ADN du gène de la bêtaglobine est d'abord totalement transcrit en ARN pré-messager (ARNpm) qui est plus long que l'ARNm utilisé dans le cytoplasme (les portions identiques entre ARNpm et ARNm apparaissent en rouge sur le graphique de ressemblance (1)). En effet l'ARNpm subit une maturation qui consiste à éliminer (excision) certaines séquences non codantes, ou introns. Les séquences codantes restantes, ou exons, sont alors liées bout à bout (épissage) de manière à former l’ARN messager (ARNm) mature qui sort du noyau et participe à la traduction (entre le codon initiateur AUG et le codon stop, ici UAA). Beaucoup de gènes sont ainsi morcelés.
Traitements obtenus avec le logiciel Anagène
Entre les gènes on constate la présence de longues séquences d'ADN, qui n'appartiennent pas à des gènes, et dont la fonction est encore mal connue mais qui semblent intervenir dans la régulation de l'expression des gènes. On parle d'ADN non codant. À cela il convient d'ajouter les introns qui ne sont pas retenus lors de la maturation de l'ARNm. Il en résulte qu'à peine 3% de l'ADN est directement impliqué dans le codage des protéines.
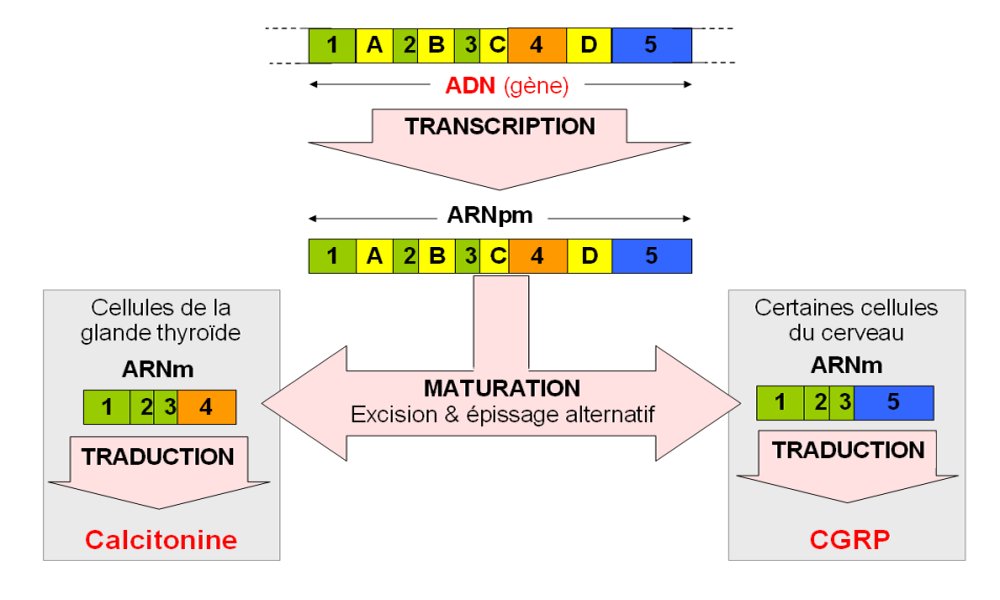
Dans certaines cellules de la glande thyroïde, le gène Calc-1 gouverne la synthèse de calcitonine, une hormone qui intervient dans la régulation de la quantité de calcium dans le sang. Dans certaines cellules du cerveau, le même gène Calc-1 commande la synthèse d’une substance permettant la communication entre neurones (neurotransmetteur), le CGRP, qui a notamment une action vasodilatatrice (augmentation du diamètre des artères).
Image d’après Principes de Biochimie, Lenhinger, Médecine-Sciences Flammarion, 1994, p. 874 (modifié), voir aussi SVT 1S, Belin 2011 p. 55 fig 5 et 6.
● Les portions codantes de l’ADN, celles correspondant à des gènes, ne représentent qu'environ 30% du génome, le reste de l'ADN a des fonctions encore mal connues. Elles comportent l'information nécessaire à la synthèse des chaînes protéiques issues de l'assemblage d'acides aminés. Cependant, chez les eucaryotes, la plupart des gènes sont morcelés car ils sont constitués d'une alternance séquences codantes, ou exons, et de séquences non codantes, ou introns.
● Ces gènes sont d'abord intégralement transcrits en ARN pré-messager (ARNpm), qui subit ensuite une maturation dans le noyau. Celle-ci consiste en une excision des introns suivie d'un épissage, c'est à dire la réunion bout à bout des exons. Cela donne naissance à l'ARN messager (ARNm).
● Les mécanismes d’épissage ne font pas toujours intervenir les mêmes exons et les mêmes introns, c’est l’épissage alternatif. Ainsi, un même ARNpm, issu d’un seul gène, peut être à l’origine de plusieurs ARNm différents donc de plusieurs protéines différentes.
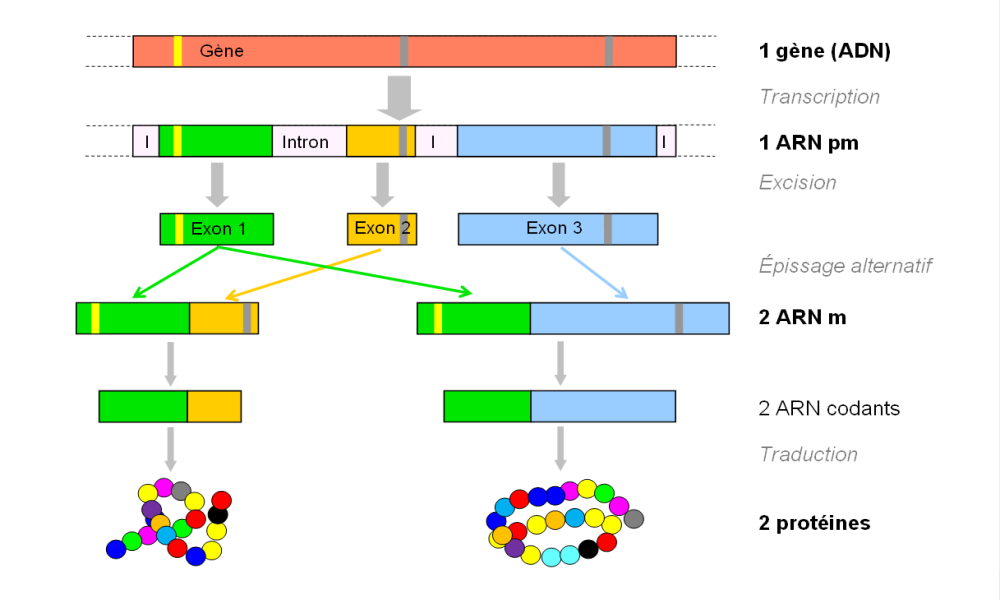 L'épissage alternatif
L'épissage alternatif BILAN
● La séquence des nucléotides des portions codantes de l'ADN représente une information qui détermine la séquence des acides aminés d'une protéine donnée grâce à un système de correspondance, le code génétique.
● La protéosynthèse fait intervenir une molécule transitoire et éphémère, l'ARNm, qui permet la sortie de l'information génétique du noyau. Chez les eucaryotes l'ADN est d'abord transcrit en ARNpm qui, après maturation (épissage alternatif), peut être à l'origine plusieurs ARNm différents traduits, selon le code génétique, en autant de protéines différentes.